Velocity Model, Building From Raw Shot Gathers Using Machine Learning & More
Introduction to Velocity Model
Seismic information translation assumes a significant part in understanding the subsurface, particularly in businesses like oil and gas investigation, ecological examinations, and geotechnical designing. A critical piece of this translation depends on making exact speed models, which portray the seismic wave speeds inside the World’s subsurface. Customarily, building these models required relentless manual understanding and calculations. In any case, with propels in AI, speed model structure has become more proficient, exact, and adaptable. In this article, we investigate the most common way of building speed models from crude shot accumulates utilizing speed model structure from crude shot assembles utilizing AI strategies.
Understanding Raw Shot Gathers
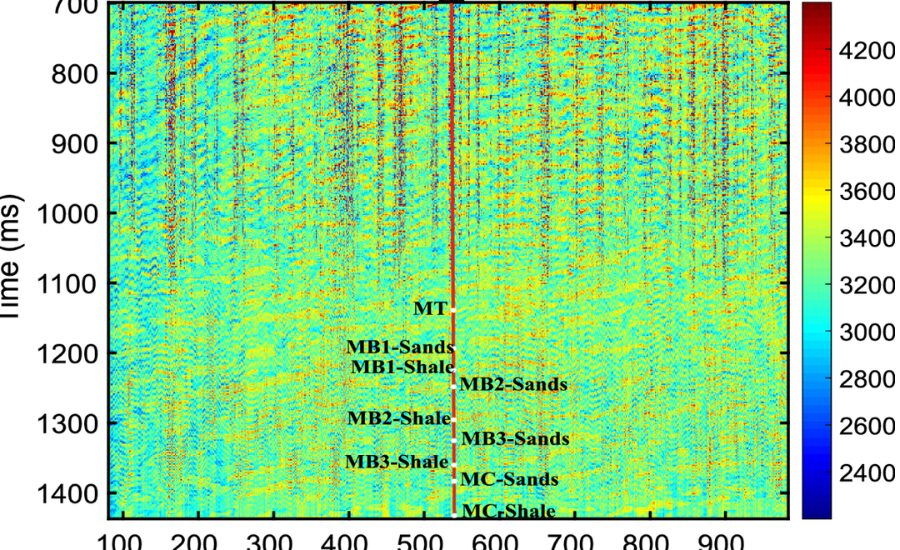
Shot accumulates are fundamental in seismic information handling. A shot assemble addresses the assortment of seismic information recorded at different recipients, or geophones, following a solitary seismic source (or “shot”) event.However, crude shot accumulates are innately uproarious and complex, requiring significant preprocessing and understanding to extricate significant data. Already, this preprocessing depended on master translators, yet today, AI models can help with mechanizing and upgrading this basic step.
Importance of Velocity Models
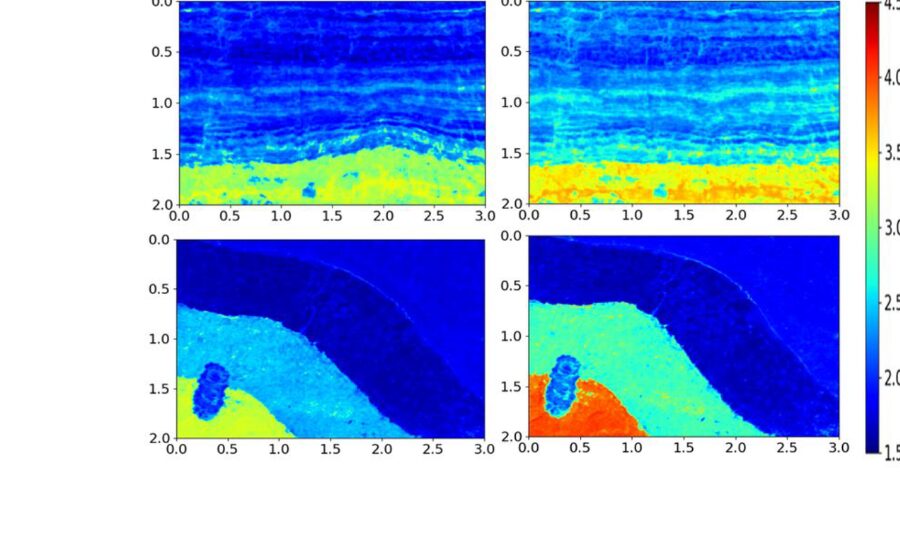
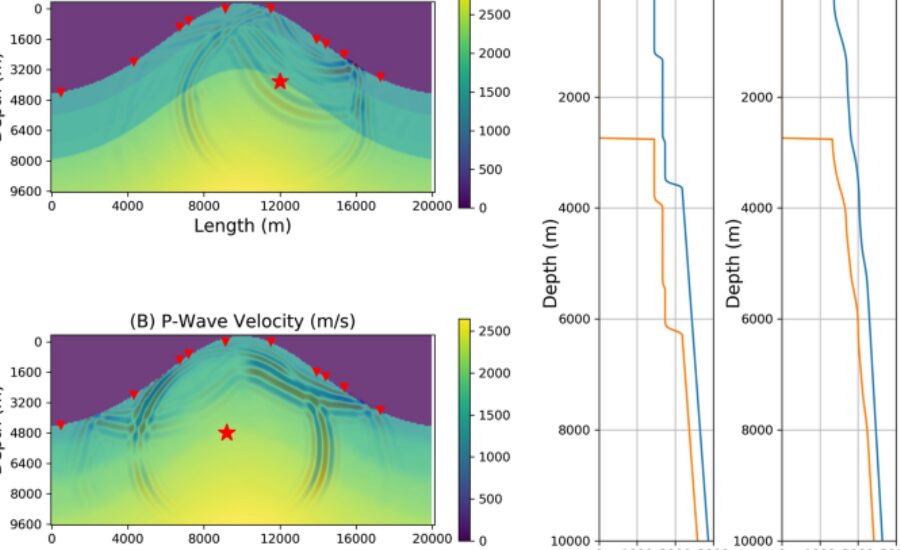
Speed models are the foundation of seismic information understanding. These models depict how seismic waves proliferate through the Earth, permitting geophysicists to distinguish different stone sorts, liquids, and land structures. Exact speed models empower the production of seismic pictures that map subsurface arrangements, which are urgent for finding regular assets, evaluating quake dangers, and settling on informed penetrating choices.
Blunders in speed models can prompt erroneous understandings, exorbitant penetrating mix-ups, or botched open doors. In that capacity, working on the precision and effectiveness of speed model structure is a high need for geophysicists, and this is where AI becomes possibly the most important factor.
Traditional Methods of Velocity Model Building
Before the ascent of AI, speed model structure was a manual and iterative interaction. This technique, while viable, was tedious and inclined to human mistake. It likewise battled to scale successfully with enormous datasets, which are progressively normal in present day seismic overviews.
The restrictions of conventional strategies lie in their reliance on master information, the intricacy of the information, and the high computational expense of over and over recreating seismic wave proliferation.
Challenges in Velocity Model Building
Building precise speed models from seismic information isn’t without challenges. To begin with, the actual information is frequently boisterous, requiring broad preprocessing. Then, the reversal cycle used to get speeds from the seismic information can be computationally serious and badly presented, implying that little changes in the information can prompt enormous changes in the speed model.
One more huge test is the subjectivity of manual translation. Various specialists might decipher similar information in an unexpected way, prompting irregularities in speed models. This subjectivity, joined with the intricacy and sheer volume of seismic information, has prodded interest in robotizing the cycle utilizing AI.
Introduction to Machine Learning in Seismic Data
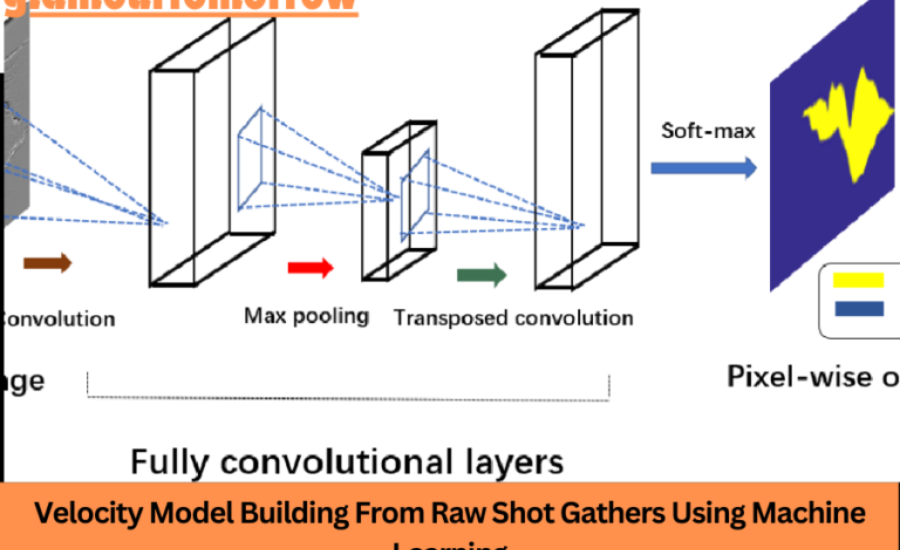
AI (ML) offers a promising answer for the difficulties of speed model structure. Via preparing calculations on huge datasets, AI models can figure out how to perceive designs in seismic information that compare to explicit subsurface highlights. This capacity takes into consideration the computerization of undertakings that were already the space of master translators, for example, recognizing layer limits and assessing seismic velocities.Machine learning models can likewise handle information quicker than customary strategies, empowering geophysicists to work with bigger datasets and produce more exact speed models.
Types of Machine Learning Used in Seismic Data
A few sorts of AI are relevant in seismic information handling, each with its assets. Administered learning, for instance, utilizes marked preparing information (where the results are known) to prepare models that can anticipate the speed model for new, concealed shot assembles. Solo learning models, then again, don’t need named information and can be utilized for assignments like grouping seismic information into various areas in light of similarity.Reinforcement learning is one more sort of AI that is building up some momentum in geophysical applications. This strategy includes preparing a specialist to go with choices in light of criticism from the climate.
Raw Shot Gathers to Velocity Model: Process Overview
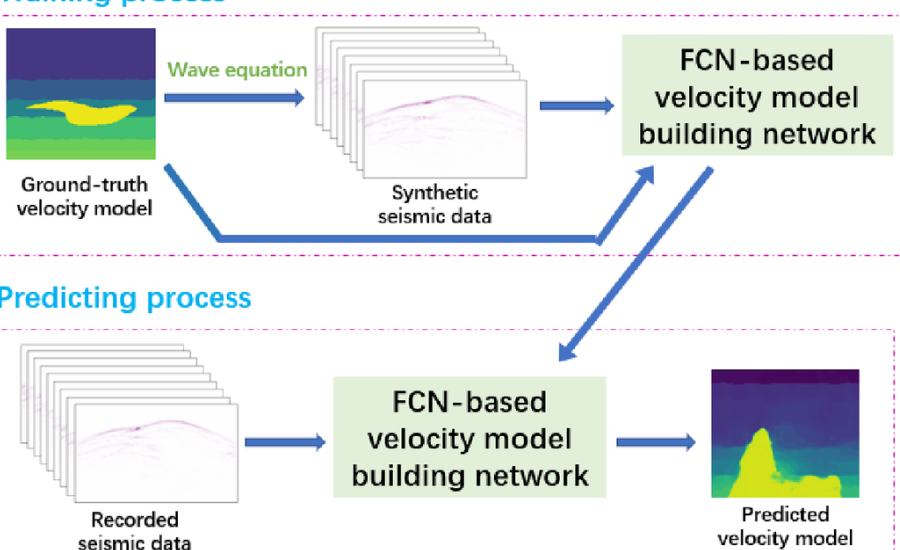
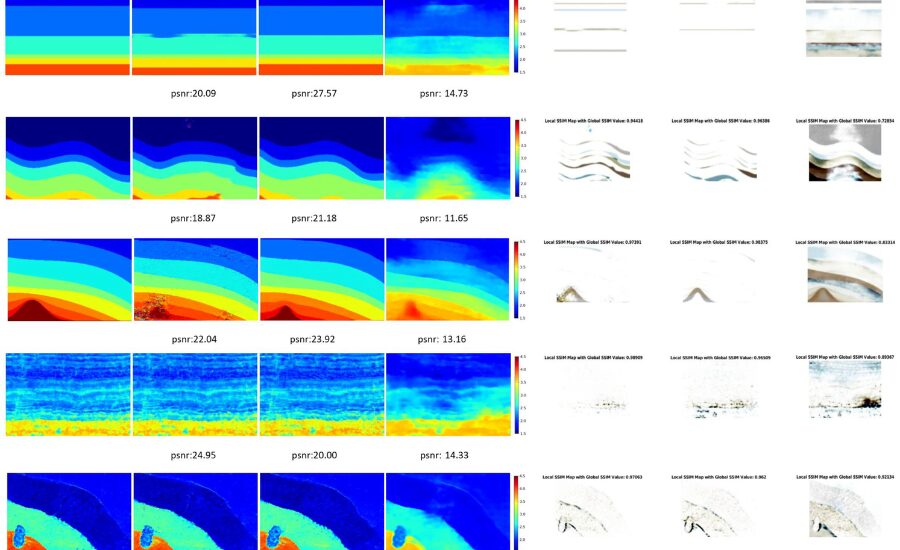
Building a speed model from crude shot assembles utilizing AI includes a few key stages. To start with, the shot accumulate information should be preprocessed to eliminate clamor and right for any contortions brought about by the World’s surface or close surface layers. Then, highlights are extricated from the shot assembles, which could incorporate properties like travel time, sufficiency, and recurrence content.Once the elements have been removed, the AI model is prepared on a dataset of marked shot accumulates, where the right speed model is known. In the wake of preparing, the model can be applied to new, unlabeled shot assembles to foresee their speed models. These forecasts are then approved against extra information or contrasted with results from customary strategies to guarantee exactness.
Data Preprocessing for Machine Learning
Information preprocessing is a basic move toward speed model structure from crude shot assembles utilizing AI, especially in seismic information examination. Crude shot accumulate information frequently contains commotion from different sources, like natural circumstances, hardware blunders, or surface waves.
Feature Engineering from Shot Gathers
In seismic information handling, this could include ascertaining seismic properties like recurrence, stage, or envelope adequacy from the shot assembles. These traits can give important data about the subsurface and help the AI model recognize different land highlights.
Besides, highlight designing can incorporate dimensionality decrease strategies, like head part examination (PCA), to lessen the intricacy of the information while safeguarding significant examples. This step is vital for guaranteeing that the AI models can work proficiently, particularly while managing enormous seismic datasets.
Labeling in Machine Learning for Velocity Models
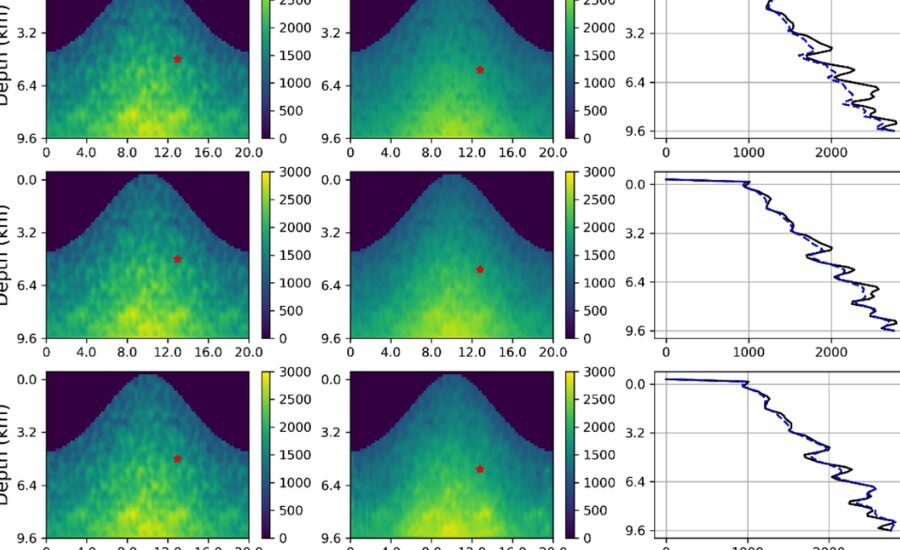
In regulated getting the hang of, naming the preparation information is perhaps of the main assignment. For seismic speed models, this regularly implies giving the right speed model to each shot assemble in the preparation set. Nonetheless, producing these marks can challenge, as it frequently requires manual translation or manufactured data.One way to deal with naming includes utilizing forward demonstrating to create engineered shot accumulates with realized speed models.
Facts
- Seismic Data Interpretation: Seismic data interpretation is crucial in industries like oil and gas exploration, environmental studies, and geotechnical engineering. It involves creating velocity models that describe the seismic wave speeds within the Earth’s subsurface.
- Velocity Models: Velocity models are essential for understanding how seismic waves propagate through the Earth, helping to identify rock types, fluids, and geological structures. Accurate velocity models are crucial for mapping subsurface formations, locating natural resources, assessing earthquake risks, and making informed drilling decisions.
- Traditional Methods: Historically, velocity model building was a manual and iterative process relying heavily on expert interpreters. These methods were time-consuming, prone to human error, and struggled with scalability when handling large datasets.
- Challenges in Velocity Model Building: Common challenges include noisy and complex seismic data, computationally intensive inversion processes, and subjective manual interpretation, which can lead to inconsistencies.
- Machine Learning (ML) in Seismic Data: ML models are used to automate and enhance the process of velocity model building from raw shot gathers, which are collections of seismic data recorded from a single seismic source event. ML can recognize patterns in seismic data corresponding to specific subsurface features, reducing the need for manual interpretation.
- Types of Machine Learning: The article discusses different ML approaches, including supervised learning (using labeled training data), unsupervised learning (clustering data based on similarities without labels), and reinforcement learning (training an agent to make decisions based on feedback).
- Data Preprocessing: Preprocessing of raw shot gather data is crucial to remove noise and correct distortions caused by surface or near-surface layers.
- Feature Engineering: Involves extracting relevant features from shot gathers, such as travel time, amplitude, and frequency content, which are crucial for training ML models. Dimensionality reduction techniques like Principal Component Analysis (PCA) are used to simplify data while retaining essential patterns.
- Labeling: Labeling in supervised learning involves providing correct velocity models for training shot gathers, which can be challenging and often requires manual interpretation or synthetic data generation.
Summary
The article “Velocity Model Building From Raw Shot Gathers Using Machine Learning” explores the evolution of velocity model building from manual, expert-driven processes to more efficient, accurate, and scalable methods using machine learning (ML). Velocity models are critical in seismic data interpretation, helping industries like oil and gas to understand subsurface conditions by describing how seismic waves propagate through the Earth. Traditional methods of building these models were labor-intensive and prone to errors, particularly when dealing with noisy and complex data.
The article highlights how ML can address these challenges by automating the interpretation process, reducing subjectivity, and handling large datasets more efficiently. It discusses various ML techniques such as supervised learning, unsupervised learning, and reinforcement learning, which can be applied to seismic data to identify subsurface features, estimate seismic velocities, and improve the overall accuracy of velocity models. Key steps in the process include preprocessing raw shot gathers to remove noise, feature engineering to extract relevant seismic properties, and labeling training data for supervised learning. The integration of ML in seismic data interpretation represents a significant advancement, making the process more robust and adaptable to modern geophysical challenges.
FAQs
1. What is a velocity model in seismic data interpretation?
A velocity model describes how seismic waves propagate through the Earth’s subsurface, allowing geophysicists to identify different rock types, fluids, and geological structures. It is crucial for mapping subsurface formations and making informed decisions in industries like oil and gas exploration.
2. Why are traditional methods of velocity model building considered challenging?
Traditional methods are challenging because they are manual, time-consuming, and prone to human error. They also struggle with scalability when dealing with large datasets and require significant expert knowledge for accurate interpretation.
3. How does machine learning improve velocity model building?
Machine learning improves velocity model building by automating the interpretation process, reducing the need for manual input, and handling large datasets more efficiently. ML models can learn to recognize patterns in seismic data corresponding to specific subsurface features, enhancing the accuracy and speed of velocity model creation.
4. What types of machine learning are used in seismic data processing?
The main types of machine learning used in seismic data processing include supervised learning (using labeled data for training), unsupervised learning (clustering data without labels), and reinforcement learning (training models based on feedback).
5. What is the role of data preprocessing in building velocity models using ML?
Data preprocessing is essential to clean and prepare raw shot gather data by removing noise and correcting distortions caused by surface or near-surface layers. This step ensures that the ML models receive high-quality input data for accurate velocity model predictions.
6. What is feature engineering in the context of seismic data processing?
Feature engineering involves extracting relevant features from shot gathers, such as travel time, amplitude, and frequency content. These features provide valuable information about the subsurface and help ML models distinguish different geological features.
7. How is labeling done for ML models in velocity model building?
Labeling involves providing the correct velocity model for each shot gather in the training dataset. This process can be challenging as it often requires manual interpretation or synthetic data generation, making it a critical step in supervised learning.
8. What are the challenges of using machine learning for velocity model building?
Challenges include the need for large, high-quality labeled datasets, handling noisy and complex seismic data, and ensuring that ML models generalize well to new, unseen data. Additionally, the computational requirements for training and deploying ML models can be significant.
Read More Information About Education At latestrular

